Skip to content
Master in AWS | Join us for the demo session on 29th December 2025 at 7:30 PM IST
Know More
Home
Trainings
Oracle DBA
Oracle DBA 19c Training
RAC DBA Training
GoldenGate Training
Oracle Cloud Training
Oracle Exadata Training
PostgreSQL Training
GCP Data Engineer Training
Azure Data Engineering
Data Analyst Training
Data Science with Gen AI
AWS Training
Devops Training
Recorded Courses
Free Courses
Real time Oracle DBA Tools and Utilities
Linux Courses for Beginner
SQL for Beginner
Paid Courses
PLSQL Course
Oracle DBA Interview Questions
Shell Scripting for Oracle DBA
Webinar
Oracle DBA Webinar
Oracle Cloud Webinar
Services
Oracle DBA Services
Graphic Designing & Video Editing
Web Development
PostgreSQL DBA Services
Application Support
About Us
Contact Us
Home
Trainings
Oracle DBA
Oracle DBA 19c Training
RAC DBA Training
GoldenGate Training
Oracle Cloud Training
Oracle Exadata Training
PostgreSQL Training
GCP Data Engineer Training
Azure Data Engineering
Data Analyst Training
Data Science with Gen AI
AWS Training
Devops Training
Recorded Courses
Free Courses
Real time Oracle DBA Tools and Utilities
Linux Courses for Beginner
SQL for Beginner
Paid Courses
PLSQL Course
Oracle DBA Interview Questions
Shell Scripting for Oracle DBA
Webinar
Oracle DBA Webinar
Oracle Cloud Webinar
Services
Oracle DBA Services
Graphic Designing & Video Editing
Web Development
PostgreSQL DBA Services
Application Support
About Us
Contact Us
Search
Search
Close this search box.
Login
Login
Free Training
Certification
Placement Drive
Gallery
Reviews
Blogs
Careers
Free Training
Certification
Placement Drive
Gallery
Reviews
Blogs
Careers
Category:
Hadoop
Home
Azure Data Engineer
Azure Data Engineer
Architecting Big Data Pipelines with Hadoop and HDFS
20 Jun, 2025
Read More
Hadoop
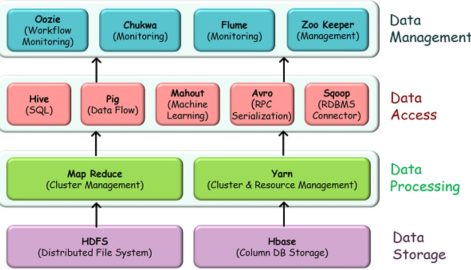
A Brief About Hadoop Ecosystem
24 Jul, 2024
Read More
Hadoop
Configure Dnsmasq for Oracle Linux for RAC scan address Configured
12 Jun, 2024
Read More
Hadoop
Cache and Persist in Pyspark
12 Mar, 2023
Read More
Hadoop
Pyspark and amazon s3 integration
03 Mar, 2023
Read More
Hadoop
Read CSV,Parquet,Avro file format using Spark
20 Mar, 2022
Read More
1
2
3
4
Book a Free Demo
Please enable JavaScript in your browser to complete this form.
Please enable JavaScript in your browser to complete this form.
Full Name
*
Mobile Number
*
Email
*
Select Course
*
--- Select Choice ---
Oracle DBA
PostgreSQL DBA
Oracle RAC
Oracle Cloud Training(OCI)
Oracle Fusion
Oracle Exadata
Azure Data Engineer
Data Analyst
Data Science
DevOps
Azure GCP Data Engineer
Generative AI
Data Science with Gen AI
GoldenGate
Oracle Integration Cloud(OIC) Training
Oracle Fusion Technical Training
Power BI
Other
Submit