








PostgreSQL Architecture for DBAs
What Is PostgreSQL DBA Architecture?
The PostgreSQL DBA Architecture defines how PostgreSQL operates internally — how memory, processes, and storage interact to manage data efficiently.
It also outlines how a DBA (Database Administrator) monitors and maintains these components to ensure smooth operation.
1. Client-Server Model
PostgreSQL operates on a client-server model, where clients and servers interact over a network. This model is fundamental to how PostgreSQL processes queries and manages connections.
- Client Application: The client can be any application that needs to interact with the database. This application sends SQL queries to the PostgreSQL server and receives the results. The communication happens via the PostgreSQL protocol over TCP/IP.
- Client Interface Library: This is a middleware that translates the client application’s requests into a format that the PostgreSQL server understands. Common libraries include libpq (the C library for PostgreSQL), JDBC (for Java), and others.
- Server Process (Postmaster Daemon Process): The server side is managed by the Postmaster daemon process. The Postmaster handles incoming connection requests, authenticates clients, and forks new backend processes for each connection. This design ensures that each client connection is isolated from the others, enhancing security and stability.
2. Backend Processes
Each client connection to PostgreSQL is handled by a dedicated backend process. This backend process executes queries on behalf of the client and returns the results.
- Postgres Backend Process: When a client connection is established, the Postmaster forks a new backend process (
postgres). This backend process handles the SQL query parsing, planning, execution, and result delivery. - PostgreSQL Instance: A PostgreSQL instance is essentially the entire environment where Postgres runs. This includes the Postmaster process, all backend processes, and various utility processes that perform maintenance tasks.
3. System Memory Management
Memory management is a critical aspect of PostgreSQL’s architecture. PostgreSQL uses both per-backend memory and shared memory.
Per Backend Memory: Each backend process has its own dedicated memory areas, which include:
work_mem: Used for operations like sorting and hashing before they spill to disk.temp_buffer: Temporary storage for operations like sorting large datasets.maintenance_work_mem: Used by maintenance operations like vacuuming and creating indexes.- Catalog Cache & Optimizer/Executor Memory: Memory used for caching system catalogs and executing SQL queries.
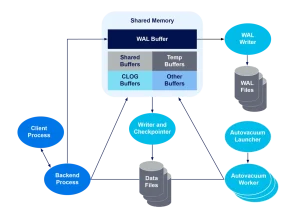
Shared Memory: Shared memory is accessible by all backend processes and is used for:
shared_buffers: This is the primary cache for PostgreSQL, where data blocks read from disk are stored. Optimizing the size ofshared_buffersis crucial for performance.WAL_buffers: Buffers for Write-Ahead Logging (WAL) data before it is written to disk.temp_buffers: Buffers for temporary tables.CLOG Buffers: Store commit log information to manage transaction states.
4. Physical and Logical Storage Layers
PostgreSQL organizes data into several layers, ensuring data integrity and performance. PostgreSQL stores data in several types of physical files on disk. These files include:
- Data Files: These are where the actual table data and indexes are stored. These files are organized into tablespaces. Each table and index corresponds to a set of files.
- WAL Files: Write-Ahead Logs (WAL) are crucial for ensuring data integrity. WAL files record every change made to the database, ensuring that even if the server crashes, no data is lost.
- Archive Files: When WAL files are archived, they are stored in archive files. This allows for point-in-time recovery and backups.
- Log Files: PostgreSQL logs various operations, errors, and information about queries in log files. These logs are essential for monitoring and troubleshooting.
5. Utility Processes
PostgreSQL includes several utility processes that perform various background tasks. These processes are critical for maintaining the database’s health and performance.
- BGWriter: The Background Writer process periodically writes dirty pages (modified pages) from the shared buffer to the disk. This helps maintain a balance between memory and disk usage.
- WAL Writer: This process is responsible for writing the contents of WAL buffers to disk. It ensures that WAL entries are flushed in a timely manner, supporting data durability.
- Auto Vacuum: Auto Vacuum automatically reclaims storage occupied by dead tuples (rows that have been updated or deleted). This process helps prevent table bloat and maintains query performance.
- Stats Collector: Gathers and maintains statistical data about the database, which the query planner uses to optimize query execution plans.
- Sys Logger: Handles logging of messages from the various server processes.
- Archiver: Responsible for copying completed WAL segments to archive storage for backup purposes.
- Checkpointer: The Checkpointer process ensures that all modified pages in memory are written to disk periodically. This reduces the recovery time after a crash.
- Logical Replication Launcher: Manages the logical replication workers that handle replication of changes to other databases.
6. PostgreSQL Shared Memory Buffers
The shared memory buffers are an integral part of PostgreSQL’s memory architecture. They include:
- Shared Buffers: Acts as a data cache, holding pages read from disk. A larger shared buffer can improve performance by reducing disk I/O.
- WAL Buffers: Holds WAL records before they are written to disk. Increasing WAL buffers can improve write performance in high-throughput environments.
- Temp Buffers: Used for temporary tables. These buffers are separate from the main shared buffer pool.
- CLOG Buffers: Used for managing transaction commit logs, essential for tracking transaction states.
-
Conclusion
PostgreSQL’s memory management is both powerful and flexible, but it requires careful tuning for different workloads. Understanding how parameters like shared_buffers, work_mem, and wal_buffers interact is essential for achieving top-tier performance, reliability, and scalability.
At Learnomate Technologies, we specialize in PostgreSQL performance optimization, tuning, and database management solutions — helping organizations achieve maximum database efficiency and stability.
At Learnomate Technologies, we make sure you not only understand such cutting-edge features but also know how to implement them in real-world projects. Whether you’re a beginner looking to break into the database world or an experienced professional upgrading your skillset—we’ve got your back with the most practical, hands-on training in Oracle technologies.
 Want to see how we teach? Head over to our YouTube channel for insights, tutorials, and tech breakdowns: www.youtube.com/@learnomate To know more about our courses, offerings, and team: Visit our official website: www.learnomate.org Let’s connect and talk tech! Follow me on LinkedIn for more updates, thoughts, and learning resources: https://www.linkedin.com/in/ankushthavali/ If you want to read more about different technologies, Check out our detailed blog posts here: https://learnomate.org/blogs/
Want to see how we teach? Head over to our YouTube channel for insights, tutorials, and tech breakdowns: www.youtube.com/@learnomate To know more about our courses, offerings, and team: Visit our official website: www.learnomate.org Let’s connect and talk tech! Follow me on LinkedIn for more updates, thoughts, and learning resources: https://www.linkedin.com/in/ankushthavali/ If you want to read more about different technologies, Check out our detailed blog posts here: https://learnomate.org/blogs/Let’s keep learning, exploring, and growing together. Because staying curious is the first step to staying ahead.
 Want to see how we teach? Head over to our YouTube channel for insights, tutorials, and tech breakdowns:
Want to see how we teach? Head over to our YouTube channel for insights, tutorials, and tech breakdowns: 
 To know more about our courses, offerings, and team: Visit our official website:
To know more about our courses, offerings, and team: Visit our official website:  Let’s connect and talk tech! Follow me on LinkedIn for more updates, thoughts, and learning resources:
Let’s connect and talk tech! Follow me on LinkedIn for more updates, thoughts, and learning resources:  If you want to read more about different technologies, Check out our detailed blog posts here:
If you want to read more about different technologies, Check out our detailed blog posts here: 