STEP 1: When a user clicks on a software or terminal a user process is allocated.
STEP 2: When user enters a user id and password it requests for a server process and a server process is allocated for that user.
STEP 3: Now the server process will go in the data dictionary cache/Row Cache and will check for the authentication, if any entry present it will authenticate the user, if not then it will check in the system data file of physical storage and will give the authentication, if user id and password exist .
STEP 4: Now when a user fires select statement query it goes through the parsing stages. The parsing stages are: ➢ Syntax check ➢ Symantec check ➢ Preparation of execution plan
STEP 5: In syntax check it will check for the position of keywords, semicolon, structure of query. These checks will be performed by the use process.
STEP 6: Now the query will go for Symantec check where two things will be checked viz. Accessibility and availability. In availability server process will check whether the table is present or not and in accessibility server process will check whether the user in is having sufficient privileges on that table or not
STEP 7: Now this query will hit the sql area of Library cache which is a part of shared pool. In sql area a unique sql_id will be given to the query and after that the query will be copied in the sql_text of sql area.
STEP 8: The sql text which is copied is given a #value which is a unique number
STEP 9: Case1:- If query is fired for the first time then the execution plan will be made, the execution plan will be made based on three parameters i.e. CPU consumption, memory and I/O. Number of execution plans will be made and out of that the best plan will be chosen and an unique #value will be given. A parse code will be generated for the plan chosen and this code will be an unique code, which will be stored in the p.code of library cache. Case 2:- If query is fired for the second time the, the server process will firstly check the data dictionary cache whether the p.code is present or not, if present then it will use that plan for execution, if not present then it will check in system data file and will use it for execution
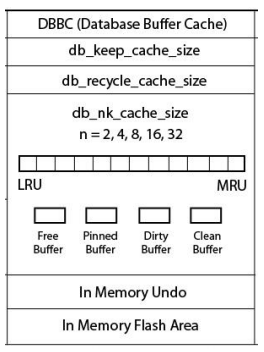
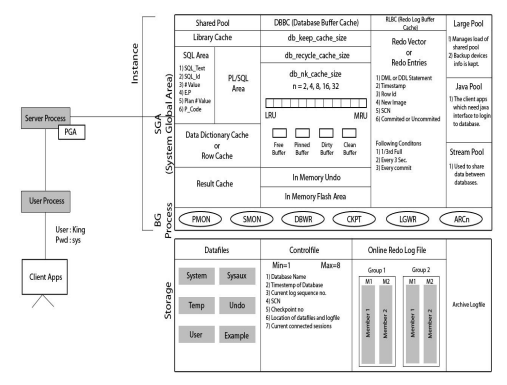
STEP 10: Based on the execution plan the server process will bring the data from the respective data files block by block in the data base buffer cache which is the part of SGA. This is nothing but fetching of data.
STEP 11: Now server process will display the data in the database buffer cache on the terminal and will also keep a record of the same in result cache area of library cache if it is enabled
Flow of Insert Statement
STEP 1: When a user clicks on a software or terminal a user process is allocated
STEP 2: When user enters a user id and password it requests for a server process and a server process is allocated for that user.
STEP 3: Now the server process will go in the data dictionary cache/Row Cache and will check for the authentication, if any entry present it will authenticate the user, if not then it will check in the system data file of physical storage and will give the authentication, if user id and password exist
STEP 4: Now when a user fires select statement query it goes through the parsing stages. The parsing stages are: ➢ Syntax check ➢ Symantec check ➢ Preparation of execution plan
STEP 5: In syntax check it will check for the position of keywords, semicolon, structure of query. These checks will be performed by the use process.
STEP 6: Now the query will go for Symantec check where two things will be checked viz. Accessibility and availability. In availability server process will check whether the table is present or not and in accessibility server process will check whether the user in is having sufficient privileges on that table or not.
STEP 7: Now this query will hit the sql area of Library cache which is a part of shared pool. In sql area a unique sql_id will be given to the query and after that the query will be copied in the sql_text of sql area.
STEP 8: The sql text which is copied is given a #value which is a unique number
STEP 9: Case1:- If query is fired for the first time then the execution plan will be made, the execution plan will be made based on three parameters i.e. CPU consumption, memory and I/O. Number of execution plans will be made and out of that the best plan will be chosen and an unique #value will be given. A parse code will be generated for the plan chosen and this code will be an unique code, which will be stored in the p.code of library cache. Case 2:- If query is fired for the second time the, the server process will firstly check the data dictionary cache whether the p.code is present or not, if present then it will use that plan for execution, if not present then it will check in system data file and will use it for execution
STEP 10:- In insert statement after the preparation of execution plan, the data comes in the database buffer cache. The old image of the dirty buffer is stored in the IN MEMORY UNDO and a copy of the dirty buffer is sent to the Redo Buffers(Redo Vectors). When the data comes in Redo vectors the header of the block is updated with UBA(Undo buffer address) ,RBA(Redo Buffer address), DBA (Data block address), SCN NO(System Change Number) any many as such unique addreses and also a information is updated whether the data is commited or uncommited .
STEP 11:- Redo vectors then write the data in online redo log groups using LGWR background process if any of the following five conditions is fulfiled. The conditions are: • Every 3 sec • Every 1MB full • Every 1/3 full • Every commit • Every graceful shutdown
STEP 12:- When the memeber of a online redo log group gets full at that time a checkpoint ocurrs will gives a signal to the CKPTr process . And at the same time the archives are generated by the ARCn background process.
STEP 13:- The CKPTr process will update the headers with SCN no. in data file and control file. Also the CKPTr process will give a signal to the DBWRn and LGWR process. DBWRn will write the data of dirty buffer in the respective data files and LGWR will write the data from redo vectors to the onlie redo log groups
ORACLE Architecture
Oracle Server:- Oracle server is a database management system that manages a large amount of data in multiuser environment so that many users can concurrently access the same data at the same time.
Components of Oracle Server:- • It consists of two components 1. Oracle Instance 2. Oracle Database
ORACLE INSTANCE:-
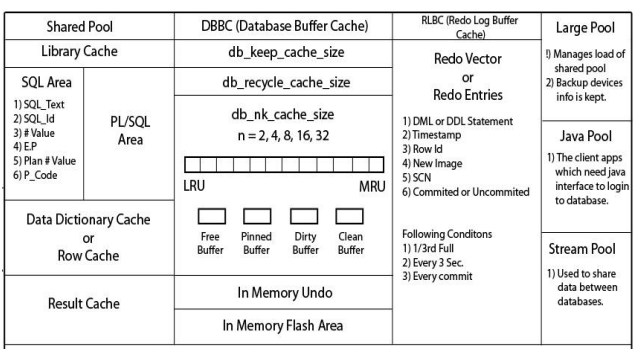
• It is a means to access an Oracle database. • Always opens one and only one database. • An instance is created during the NOMOUNT stage of the database startup after the parameter file has been read. • It consist of two components: 1. System Global Area (SGA) 2. Background Processes • When instance is started, SGA is allocated and Background processes are started
SYSTEM GLOBAL AREA
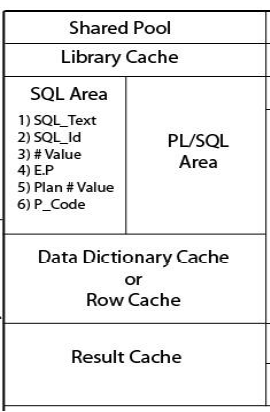
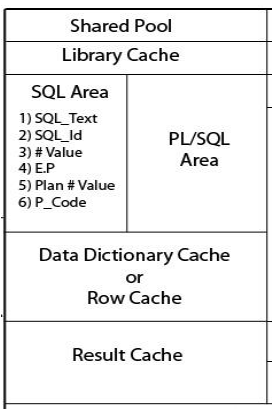
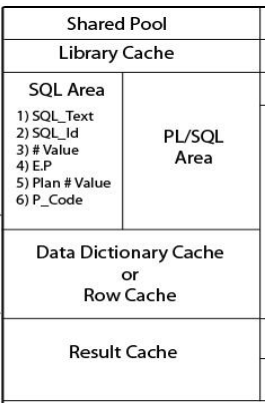
SHARED POOL:- • Library cache – SQL Area – PL/SQL Area • Data dictionary cache • Result cache
SHARED POOL:-
• Library cache – SQL Area • SQL Text • SQL Id • # value • E.P • Plan # value • P_code
SHARED POOL:- • Data dictionary cache – Data dictionary view of System tablespace – Availability – Accessibility • Result cache – Snapshot of result
RLBC (Redo Log Buffer Cache) • Redo Vector – DML or DDL Statement – Timestamp of transaction – Row Id – New Image – SCN – Committed or Uncommited
Large Pool • Managed load of shared pool • Backup devices info is kept Java Pool • To run Java interface tools Stream Pool • Share data between databases
PMON (Process Monitor): • The process monitor database process. •The Process Monitor (PMON) performs process recovery when a user process fails • PMON is responsible for cleaning up the cache and freeing resources that the process was using •For example, it resets the status of the active transaction table, releases locks, and removes the process ID from the list of active processes.
SMON(System Monitor) • SMON is an Oracle background process created when you start a database instance. • The SMON process performs instance recovery, cleans up after dirty shutdowns and coalesces adjacent free extents into larger free extents. • SMON wakes up every 5 minutes to perform housekeeping activities. • SMON must always be running for an instance. If not, the instance will terminate
DBWRn (Database Writer Process): • DBWR (DataBase WRiter) is an Oracle background process created when you start a database instance. • The DBWR writes modified data (dirty buffers) from the SGA into the Oracle database files. •When the SGA data buffer cache fills the DBWR process selects buffers using an LRU algorithm and writes them to disk. • There can be multiple database writer processes named DBWn.
LGWR (Log Writer Process) • LGWR (LoG WRiter) is an Oracle background process created when you start a database instance. • The LGWR writes the redo log buffers to the on-line redo log files. • If the on-line redo log files are mirrored, all the members of the group will be written out simultaneously
CKPTr (Checkpoint Process): • CKPT (Oracle Checkpoint Process) is an Oracle background process that timestamps all datafiles and control files to indicate that a checkpoint has occurred. • The “DBWR checkpoints” statistic (v$sysstat) indicates the number of checkpoint requests completed
ARCn (Archive process): • ARCn is an oracle background process responsible for copying the entirely filled online redo log file to the archive log • Once these files have been copied, they can be overwritten • The n in ARCn represents the sequence number of the archiver process. • A single oracle instance can have 10 (ARC0 to ARC0) archiver processes associated with it. •ARCn process is however, only activated when the database is running in ARCHIVELOG mode and the LOG_ARCHIVE_START initialization parameter is set to true