







Data Engineering Flow
In today’s data-driven world, managing data from various sources can be daunting. However, with a structured approach, you can streamline the process and harness the full potential of your data. Here’s a step-by-step guide to help you navigate the data flow effectively:
1. Gathering Data from Multiple Sources
Begin by collecting data from diverse sources like databases, data warehouses, sensors, and social media platforms. Aim to bring all this data together into a centralized storage solution, such as a Data Lake. This consolidation ensures easier access and management of your data assets.
2. Implementing an Ingestion Framework
Next, deploy a reliable ingestion framework to seamlessly bring data from different sources into your storage platform. Tools like Azure Data Factory or AWS Glue can assist in this process, ensuring smooth data transfer and integration.
3. Processing Data: Embracing ELT Methodology
Once the data is ingested, it’s time to process it. Follow the ELT (Extract, Load, Transform) methodology, where data is first loaded into the storage and then transformed according to your business needs. This involves tasks like data cleansing, aggregation, and joining to enhance data quality and relevance.
4. Serving Layer: Making Data Actionable
After processing, move the data to the serving layer, where visualization tools like Tableau or PowerBI come into play. Connect these tools to your storage solution, allowing stakeholders to visualize data insights graphically and make informed decisions.

Choosing Your Data Pipeline: Azure vs. AWS
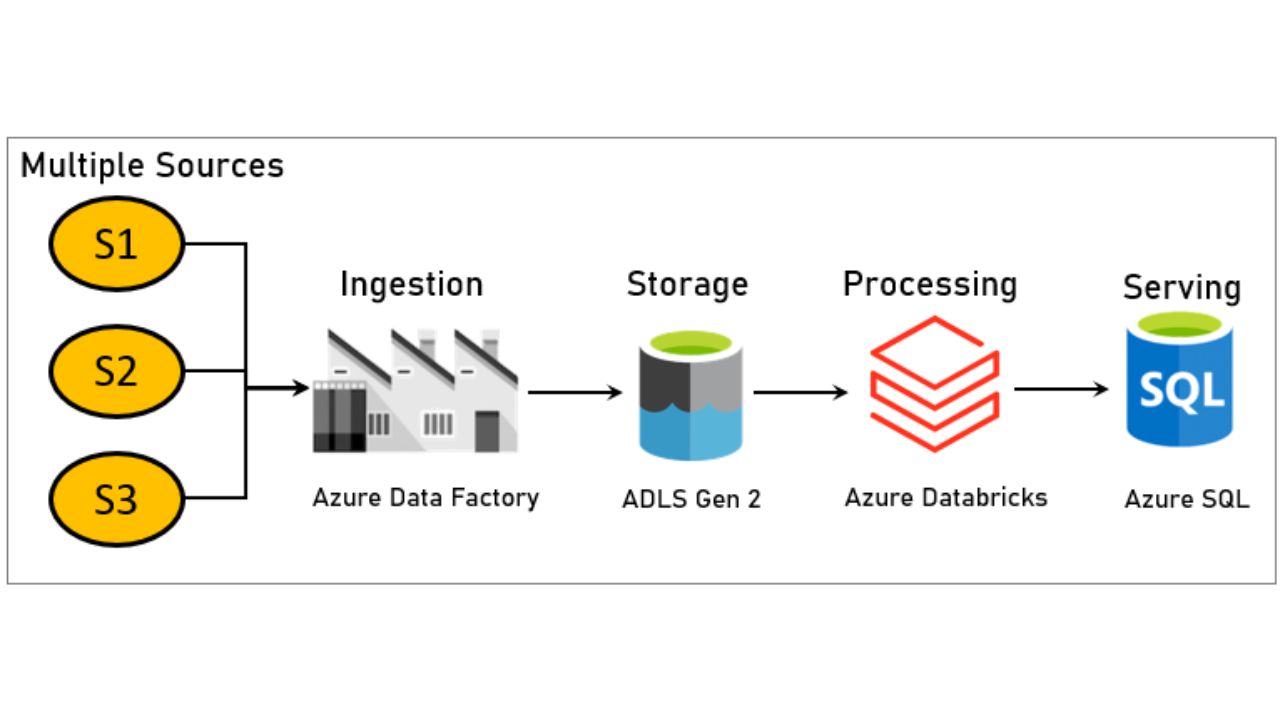
End-to-End Big Data Pipeline in Azure
In Azure, leverage tools like Azure Data Factory, Azure Databricks, or Synapse for ingestion and processing, and Azure SQL or Cosmos DB for serving.
In brief:-
Multiple Sources > Azure Data Factory-ADF (Ingestion) -> ADLS Gen2 (Storage) -> Azure Databricks/Synapse (Processing) -> Azure SQL/Cosmos DB (Serving)

End-to-End Big Data Pipeline in AWS
Alternatively, in AWS, utilize AWS Glue for ingestion, Amazon S3 for storage, and Athena or Redshift for processing, with AWS RDS or DynamoDB for serving.
In brief:-
Multiple Sources -> AWS Glue (Ingestion) -> Amazon S3 (Storage) -> Athena/Redshift (Processing) -> AWS RDS/DynamoDB (Serving)

By following these steps and leveraging the right tools, you can navigate the data flow with confidence, unlocking valuable insights and driving innovation within your organization.
_____________________________________________________________________________
Ready to take your data engineering journey to the next level?
At Learnomate Technologies, we pride ourselves on offering top-notch training in data engineering. Whether you’re diving into the world of Azure, AWS, or any other aspect of data management, our expert-led courses will equip you with the skills you need to succeed.
For even more insights and tips, be sure to check out our YouTube channel at www.youtube.com/@learnomate, where we have a community of over 23k subscribers eagerly sharing their knowledge and experiences.
Visit our website at www.learnomate.org to explore our range of courses and kickstart your learning today. Let’s embark on this exciting journey together! Do follow me on Linkedin at Ankush Thavali where I keep posting many other technical stuff.
